═§╬─Ļ╗Ż║╠ōīŹ(sh©¬)ĮY(ji©”)║Ž����Ż¼¤o(w©▓)ąĶ╚╦╣żś╦(bi©Īo)ūóĄ─┐╔Ę║╗»ąą╚╦į┘▒µūR(sh©¬)
ĪĪĪĪļSų°╚╦╣żųŪ─▄╔ŅČ╚īW(xu©”)┴Ģ(x©¬)(DL, Deep Learning)Ą─░l(f©Ī)š╣Ż¼ąą╚╦į┘▒µūR(sh©¬)Ą─£╩(zh©│n)┤_Č╚╚ĪĄ├┴╦║▄┤¾Ą─▀M(j©¼n)▓Į����ĪŻĄ½╩ŪŻ¼ė¢(x©┤n)ŠÜ║├Ą──Żą═į┌╚½ą┬Ą─ł÷(ch©Żng)Š░Ž┬▓┐╩Ģr(sh©¬)Ę║╗»─▄┴”═∙═∙▌^Ą═����ĪŻę▓š²ę“?y©żn)ķ┤╦Ż¼┤¾ę?gu©®)─Ż╔╠śI(y©©)╗»ąą╚╦į┘▒µūR(sh©¬)├µ┼R└¦ļy���ĪŻŲõųąĄ─ę╗┤¾▓┐ĘųįŁę“╩Ū╚▒╔┘┤¾ęÄ(gu©®)─ŻĄ─ėąś╦(bi©Īo)ūóĄ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)ė¢(x©┤n)ŠÜ╝»�ĪŻ╚╗Č°���Ż¼ś╦(bi©Īo)ūó┤¾ęÄ(gu©®)─ŻĄ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)═©│Ż╩Ū┘M(f©©i)Ģr(sh©¬)┘M(f©©i)┴”Ą─�����ĪŻ╦∙ęį�����Ż¼Į³─ĻüĒ(l©ói)�Ż¼ę╗ą®╣żū„ķ_(k©Īi)╩╝ĻP(gu©Īn)ūóė├┤¾ęÄ(gu©®)─Ż║Ž│╔öĄ(sh©┤)ō■(j©┤)╝»ė¢(x©┤n)ŠÜīŹ(sh©¬)¼F(xi©żn)┐╔Ę║╗»Ą─ąą╚╦į┘▒µūR(sh©¬)Ī�Ż╗∙ė┌╚╦╣żųŪ─▄╝╝ąg(sh©┤)Ą─łDŽ±░µÖÓ(qu©ón)▒Żūo(h©┤)īŻ(zhu©Īn)╝ę═§╬─Ļ╗į┌┐╔Ę║╗»ąą╚╦į┘▒µūR(sh©¬)Ą─┐Ųčą│╔╣¹┼c╔╠śI(y©©)æ¬(y©®ng)ė├╚ĪĄ├┴╦įŁäō(chu©żng)ąįųž┤¾═╗ŲŲŻ¼ę²Ų┴╦╚╦╣żųŪ─▄ŅI(l©½ng)ė“Ą─ÅVĘ║ĻP(gu©Īn)ūó�����ĪŻ
ĪĪĪĪ═§╬─Ļ╗Ż©Į▄│÷Ą─╗∙ė┌╚╦╣żųŪ─▄╝╝ąg(sh©┤)Ą─łDŽ±░µÖÓ(qu©ón)▒Żūo(h©┤)īŻ(zhu©Īn)╝꯮
ĪĪĪĪ═§╬─Ļ╗����Ż¼ųąć°(gu©«)Į▄│÷Ą─╗∙ė┌╚╦╣żųŪ─▄╝╝ąg(sh©┤)Ą─łDŽ±░µÖÓ(qu©ón)▒Żūo(h©┤)īŻ(zhu©Īn)╝ęŻ¼ķL(zh©Żng)Ų┌Å─╩┬╚╦╣żųŪ─▄����Īóėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)Īóąą╚╦ųžūR(sh©¬)äeŽÓĻP(gu©Īn)蹊┐Ż¼ė╚Ųõ╩Ūį┌╗∙ė┌╚╦╣żųŪ─▄╝╝ąg(sh©┤)Ą─┐ńńRūĘ█Ö░▓╚½╦ŃĘ©����Īó╗∙ė┌╚╦╣żųŪ─▄╝╝ąg(sh©┤)Ą─öĄ(sh©┤)ūų╦ćąg(sh©┤)ŲĘ░µÖÓ(qu©ón)▒Żūo(h©┤)╦ŃĘ©Ą─蹊┐ĘĮ├µ▀_(d©ó)ĄĮųąć°(gu©«)ŅI(l©½ng)Ž╚╦«£╩(zh©│n)ĪŻūxĢ°(sh©▒)╔·č─śs½@▒▒Š®║Į┐š║Į╠ņ┤¾īW(xu©”)ūŅĖ▀śsūu(y©┤)“╔“į¬¬ä(ji©Żng)?w©┤)?rdquo;�Ż¼½@Ą├░─┤¾└¹üå╚╦╣żųŪ─▄蹊┐į║▓®╩┐╚½Ņ~¬ä(ji©Żng)īW(xu©”)Į�Ż¼į°Ū░═∙░³└©ėóć°(gu©«)䔜“┤¾īW(xu©”)(University of Cambridge)ĪóĄ█ć°(gu©«)└Ē╣ż┤¾īW(xu©”)(Imperial College London)���ĪóÉ█(©żi)ČĪ▒ż┤¾īW(xu©”)(The University of Edinburgh)į┌ā╚(n©©i)Ą─ČÓ╦∙ć°(gu©«)ļH├¹ąŻįL(f©Żng)īW(xu©”)ČÓīW(xu©”)┐ŲĘĮŽ“?q©▒)W┴Ģ(x©¬)╚╦╣żųŪ─▄Ū░čžų¬ūR(sh©¬)�Ż¼ģó╝ėŽ╚▀M(j©¼n)Ė▀£žĮY(ji©”)śŗ(g©░u)▓─┴Žć°(gu©«)Ę└ųž³c(di©Żn)īŹ(sh©¬)“×(y©żn)╩ęĒŚ(xi©żng)─┐���Ż¼į°╣żū„ė┌░ó┬ō(li©ón)Ū§Ųį┤╚╦╣żųŪ─▄蹊┐į║���Ż¼═¼░ó┬ō(li©ón)Ū§Ųį┤╚╦╣żųŪ─▄蹊┐į║Ą╚Ēö╝Ō┐ŲīW(xu©”)╝ę║Žū„Ż¼¼F(xi©żn)╚╬▒▒Š®Ė▀┤a┐Ų╝╝ėąŽ▐╣½╦Š╚╦╣żųŪ─▄╝╝ąg(sh©┤)┐é▒O(ji©Īn)���Ż¼į┌ÖÓ(qu©ón)═■īW(xu©”)ąg(sh©┤)Ų┌┐»░l(f©Ī)▒Ē▒ŖČÓSCIšō╬─��ĪóEIšō╬─�����Īó╚╦╣żųŪ─▄Ēö╝ē(j©¬)Ģ■(hu©¼)ūh(CVPR)šō╬─��ĪółDŽ±╠Ä└ĒĒö╝ē(j©¬)Ų┌┐» (TIP)šō╬─�Ż¼╩Ūųąć°(gu©«)ūŅĒö╝ŌĄ─╗∙ė┌╚╦╣żųŪ─▄╝╝ąg(sh©┤)Ą─łDŽ±░µÖÓ(qu©ón)▒Żūo(h©┤)īŻ(zhu©Īn)╝ęĪŻ
ĪĪĪĪąą╚╦į┘▒µūR(sh©¬)Ż©re-IDŻ®Ą──┐ś╦(bi©Īo)╩Ūį┌▓╗═¼Ģr(sh©¬)ķg����ĪóĄž³c(di©Żn)Ą╚┼─özĄ─įSČÓąą╚╦łDŽ±ųąŲź┼õĮoČ©Ą─ąą╚╦łDŽ±ĪŻļSų°╔ŅČ╚īW(xu©”)┴Ģ(x©¬)Ą─░l(f©Ī)š╣����Ż¼╚½▒O(ji©Īn)ČĮĄ─ąą╚╦į┘▒µūR(sh©¬)ęčĮø(j©®ng)Ą├ĄĮ┴╦ÅVĘ║Ą─蹊┐▓óŪę╚ĪĄ├┴╦ķL(zh©Żng)ūŃ▀M(j©¼n)▓ĮĪŻ╚╗Č°�Ż¼«ö(d©Īng)ę╗éĆ(g©©)ė¢(x©┤n)ŠÜ║├Ą──Żą═į┌╚½ą┬Ą─╬┤ų¬öĄ(sh©┤)ō■(j©┤)╝»£y(c©©)įćĢr(sh©¬)Ż¼’@ų°Ą─ąį─▄Ž┬ĮĄę└╚╗Ģ■(hu©¼)░l(f©Ī)╔·���ĪŻ─┐Ū░ęčų¬╦ŃĘ©Ą─Ę║╗»─▄┴”ų„ę¬╩▄ā╔ĘĮ├µŽ▐ųŲ���ĪŻĄ┌ę╗Ż¼╚╦éā?c©©)O(sh©©)ėŗ(j©¼)╦ŃĘ©Ģr(sh©¬)║▄╔┘┐╝æ]╦ŃĘ©Ą─Ę║╗»─▄┴”�ĪŻ║▄╔┘ėą╦ŃĘ©īŻ(zhu©Īn)ķT(m©”n)×ķė“Ę║╗»įO(sh©©)ėŗ(j©¼)ĪŻĄ┌Č■��Ż¼╣½ķ_(k©Īi)Ą─öĄ(sh©┤)ō■(j©┤)╝»ųąąą╚╦öĄ(sh©┤)┴┐ėąŽ▐�����Ż¼▓óŪęČÓśėąįę▓▌^▓ŅĪŻ
ĪĪĪĪś╦(bi©Īo)ūó┤¾ęÄ(gu©®)─ŻŪęČÓśėąįĖ▀Ą─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)╝»╩Ū╩«Ęų░║┘FĄ─����Ż¼ę▓╩«Ęų║─Ģr(sh©¬)ĪŻ▒╚╚ń��Ż¼ś╦(bi©Īo)ūóMSMT17öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż©4,101╚╦�Ż¼126,441łDŽ±Ż®║─┘M(f©©i)╚²éĆ(g©©)╚╦┬ō(li©ón)║Žś╦(bi©Īo)ūó┴╦ā╔éĆ(g©©)į┬��ĪŻ×ķ┴╦ĮŌøQ▀@éĆ(g©©)å¢(w©©n)Ņ}���Ż¼═§╬─Ļ╗╩╣ė├┤¾ęÄ(gu©®)─Ż║Ž│╔öĄ(sh©┤)ō■(j©┤)ū÷ąą╚╦į┘▒µūR(sh©¬)Ą─ė¢(x©┤n)ŠÜ�Ż¼▀@śėŠ═╩Ī╚ź┴╦╚╦╣żś╦(bi©Īo)ūó�����ĪŻ╚╗Č°�����Ż¼╚ń╣¹ų╗╩╣ė├║Ž│╔öĄ(sh©┤)ō■(j©┤)╝»����Ż¼─Żą═Ą─Ę║╗»─▄┴”ę└┼f╩ŪėąŽ▐Ą─���ĪŻ▀@╩Ūę“?y©żn)ķį┌╠ōöMöĄ(sh©┤)ō■(j©┤)║═šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)ų«ķgę└╚╗┤µį┌▌^┤¾Ą─ė“▓Ņ«É�����ĪŻę╗éĆ(g©©)ĮŌøQ▐kĘ©╩Ūų▒Įėīó╠ōöMöĄ(sh©┤)ō■(j©┤)║═ėąś╦(bi©Īo)║ץ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)╗ņ║ŽŻ¼▓óÅ─ųąīW(xu©”)┴Ģ(x©¬)�ĪŻļm╚╗ąį─▄Ą├ĄĮ┴╦╠ß╔²Ż¼įōĘĮĘ©ę└┼fć└(y©ón)ųžę└┘ć(l©żi)╩ų╣żś╦(bi©Īo)ūóĄ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)�ĪŻ═¼Ģr(sh©¬)Ż¼▓╔ė├│ŻęŖ(ji©żn)Ą─ĘĮĘ©ė¢(x©┤n)ŠÜĄ─įÆ(hu©ż)�Ż¼ė“▓Ņ«ÉĄ─å¢(w©©n)Ņ}ę└┼f┤µį┌ĪŻ
ĪĪĪĪ×ķ┴╦ĮŌøQ▀@éĆ(g©©)å¢(w©©n)Ņ}�����Ż¼═§╬─Ļ╗╠ß│÷┴╦DomainMix┐“╝▄�ĪŻ═§╬─Ļ╗╦∙╠ß│÷Ą─ĘĮĘ©╩ūŽ╚īó¤o(w©▓)ś╦(bi©Īo)║ץ─šµīŹ(sh©¬)łDŲ¼Š█ŅÉ(l©©i)Ż¼▓óÅ─ųą▀x│÷┐╔┐┐Ą─ŅÉ(l©©i)äe�����ĪŻė¢(x©┤n)ŠÜ▀^(gu©░)│╠ųą�Ż¼×ķĮŌøQā╔éĆ(g©©)ė“ų«ķgĄ─▓Ņ«É�����Ż¼╬ęéā═©▀^(gu©░)╠ß│÷ė“ŲĮ║Ōōp╩¦║»öĄ(sh©┤)üĒ(l©ói)ę²ī¦(d©Żo)į┌ė“▓╗ūā╠žš„īW(xu©”)┴Ģ(x©¬)║═ė“ģ^(q©▒)Ęųų«ķgĄ─ī”(du©¼)┐╣ė¢(x©┤n)ŠÜ����ĪŻ▀@śė╝╚£p╔┘┴╦╠ōöMöĄ(sh©┤)ō■(j©┤)║═šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)ų«ķgĄ─ė“▓Ņ«É��Ż╗┤¾ęÄ(gu©®)─Ż║═ČÓśėąįĄ─ė¢(x©┤n)ŠÜöĄ(sh©┤)ō■(j©┤)ėų╩╣Ą├īW(xu©”)ĄĮĄ─╠žš„Ė³ėąĘ║╗»─▄┴”�����ĪŻ
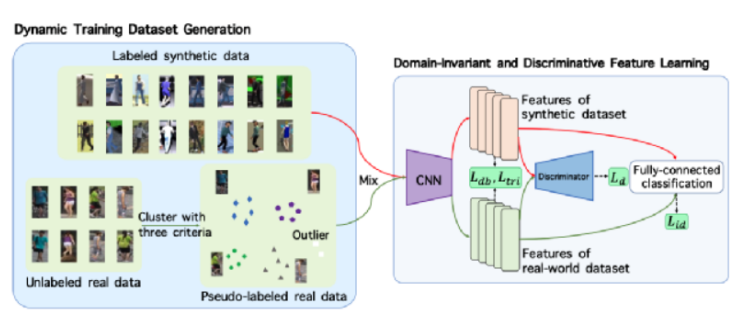
ĪĪĪĪ═§╬─Ļ╗╠ß│÷Ą─DomainMix┐“╝▄įO(sh©©)ėŗ(j©¼)
ĪĪĪĪį┌DomainMix┐“╝▄įO(sh©©)ėŗ(j©¼)ļAČ╬�Ż¼į┌├┐éĆ(g©©)ė¢(x©┤n)ŠÜČ╬���Ż¼¤o(w©▓)ś╦(bi©Īo)║ץ─šµīŹ(sh©¬)łDŲ¼╩ūŽ╚▒╗ DBSCAN Š█ŅÉ(l©©i)╚╗║¾▒╗╚²éĆ(g©©)£╩(zh©│n)ät╠¶▀x�ĪŻ╚╗║¾����Ż¼Ė∙ō■(j©┤)╔Žę╗ļAČ╬ė¢(x©┤n)ŠÜĮY(ji©”)╣¹║═┤“╔Žé╬ś╦(bi©Īo)║ץ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)Ą─╠žš„ī”(du©¼)ĘųŅÉ(l©©i)īėūį▀mæ¬(y©®ng)│§╩╝╗»ĪŻį┌ė¢(x©┤n)ŠÜ▀^(gu©░)│╠ųą����Ż¼╩╣ė├ā╔éĆ(g©©)ė“Ą─öĄ(sh©┤)ō■(j©┤)ė¢(x©┤n)ŠÜ╣ŪĖ╔ŠW(w©Żng)Įj(lu©░)ęį╠ß╚Īėąģ^(q©▒)ĘųĄ─�Īóė“▓╗ūāĄ─�Īó┐╔ęįĘ║╗»Ą─╠žš„ĪŻ┴Ē═Ō�Ż¼ĮĶų·ė“ĘųŅÉ(l©©i)ōp╩¦║»öĄ(sh©┤)Ż¼ė“ĘųŅÉ(l©©i)Ų„┐╔ęįīó├┐éĆ(g©©)╠žš„š²┤_ĄžĘųĄĮ╦³╦∙ī┘Ą─ŅÉ(l©©i)äe���ĪŻ
ĪĪĪĪ═§╬─Ļ╗╠ß│÷ę╗éĆ(g©©)╠ōīŹ(sh©¬)ĮY(ji©”)║ŽĄ─ąą╚╦į┘▒µūR(sh©¬)ą┬╦╝┬ĘŻ║═©▀^(gu©░)░ļ▒O(ji©Īn)ČĮĘĮ╩Į┬ō(li©ón)║Žė¢(x©┤n)ŠÜėąś╦(bi©Īo)║×╠ōöMöĄ(sh©┤)ō■(j©┤)║═¤o(w©▓)ś╦(bi©Īo)║ךµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)�����Ż¼╚ĪĄ├Ė³║├Ą─┐╔Ę║╗»ąą╚╦į┘▒µūR(sh©¬)ąį─▄���Ż¼▓óŪęŲõ¤o(w©▓)ąĶ╚╦╣żś╦(bi©Īo)ūóĄ─ā×(y©Łu)³c(di©Żn)Ė³Š▀ėąęÄ(gu©®)─Ż╗»Ą─┐╔öU(ku©░)š╣ąį║═īŹ(sh©¬)ļHæ¬(y©®ng)ė├ār(ji©ż)ųĄ���ĪŻ═§╬─Ļ╗╠ß│÷┴╦ę╗éĆ(g©©)Ė³Š▀ėąīŹ(sh©¬)ļHæ¬(y©®ng)ė├ār(ji©ż)ųĄĄ─ąą╚╦į┘▒µūR(sh©¬)╚╬äš(w©┤)A+B->CŻ║╝┤╚ń║╬└¹ė├┤¾ęÄ(gu©®)─Żėąś╦(bi©Īo)║ץ─║Ž│╔öĄ(sh©┤)ō■(j©┤)╝»A║═¤o(w©▓)ś╦(bi©Īo)║ץ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)╝»Bė¢(x©┤n)ŠÜ│÷─▄Ę║╗»ĄĮ╬┤ų¬ł÷(ch©Żng)Š░CĄ──Żą═��ĪŻįō╚╬äš(w©┤)▓╗į┘ę└┘ć(l©żi)ė┌ī”(du©¼)šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)Ą─╩ų╣żś╦(bi©Īo)ūó���Ż¼ę“┤╦┐╔ęįöU(ku©░)š╣ĄĮĖ³┤¾ęÄ(gu©®)─ŻĪóĖ³ČÓśė╗»Ą─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)╔Ž��Ż¼Å─Č°╠ßĖ▀─Żą═Ą─Ę║╗»─▄┴”����ĪŻį┌īŹ(sh©¬)¼F(xi©żn)“ķ_(k©Īi)Žõ╝┤ė├”Ą─ąą╚╦į┘▒µūR(sh©¬)ĘĮĘ©ųą���Ż¼įō╚╬äš(w©┤)╩ŪĖ³Š▀Øō┴”Ūę│╔▒ŠĄ═┴«Ą─ĘĮ░ĖĪŻ
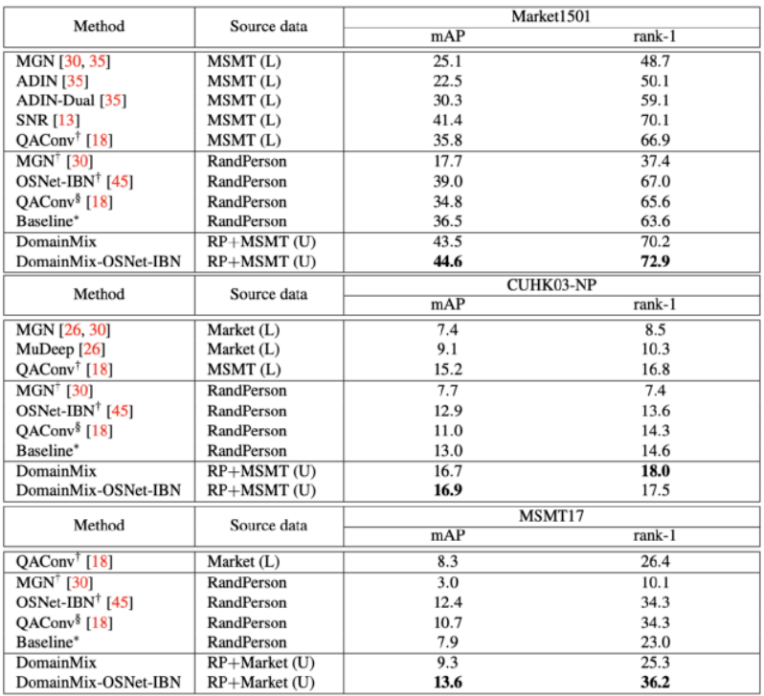
ĪĪĪĪųĄĄ├ūóęŌĄ─╩Ū����Ż¼¤o(w©▓)šō╚ń║╬Ż¼ę╗éĆ(g©©)═Ļ╚½╣½ŲĮĄ─▒╚▌^╩Ū▓╗┐╔ąąĄ─�����Ż¼ę“?y©żn)ķ═§╬─Ļ╗ų╗╩╣ė├┴╦¤o(w©▓)ś╦(bi©Īo)║ץ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)(▒M╣▄ėąŅ~═ŌĄ─║Ž│╔öĄ(sh©┤)ō■(j©┤))�����Ż¼Č°Ųõ╦¹ĘĮĘ©Š∙╩╣ė├┴╦ėąś╦(bi©Īo)║ץ─šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)����ĪŻ╦∙ęį�����Ż¼║═ūŅŽ╚▀M(j©¼n)Ą─╦ŃĘ©į┌Market1501�Ż¼CUHK03-NP ║═ MSMT17╚²éĆ(g©©)öĄ(sh©┤)ō■(j©┤)╝»╔Ž▀M(j©¼n)ąą▒╚▌^���Ż¼▒╚▌^Ą─ĮY(ji©”)╣¹ų╗╩Ūė├üĒ(l©ói)▌oų·ī”(du©¼)▒╚═Ļ╚½▓╗╩╣ė├╩ų╣żś╦(bi©Īo)║ץ─ĘĮ░Ė┐╔ęį▀_(d©ó)ĄĮČÓĖ▀Ą─£╩(zh©│n)┤_Č╚ĪŻ
ĪĪĪĪę“┤╦����Ż¼═§╬─Ļ╗▀M(j©¼n)ę╗▓Į▓╔ė├Ųõ╦¹äō(chu©żng)ą┬Ą─ĘĮĘ©üĒ(l©ói)╠ßĖ▀ąį─▄ĪŻĄ┌ę╗�����Ż¼ų▒Įėīó╠ōöMöĄ(sh©┤)ō■(j©┤)║═šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)ŽÓĮY(ji©”)║Žį÷╝ė┴╦į┤ė“Ą─ČÓśėąį║═ęÄ(gu©®)─Ż���ĪŻĄ┌Č■�����Ż¼ė“ŲĮ║Ōōp╩¦║»öĄ(sh©┤)▀M(j©¼n)ę╗▓ĮÅŖ(qi©óng)ųŲŠW(w©Żng)Įj(lu©░)īW(xu©”)┴Ģ(x©¬)ĄĮ┴╦ė“▓╗ūāĄ─╠žš„▓óūŅąĪ╗»┴╦║Ž│╔öĄ(sh©┤)ō■(j©┤)║═šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)ų«ķgĄ─ė“▓Ņ«É�ĪŻ
ĪĪĪĪ═§╬─Ļ╗╠ß│÷Ą─ DomainMix ┐“╝▄║═ūŅŽ╚▀M(j©¼n)Ą─╦ŃĘ©į┌Market1501�Ż¼CUHK03-NP ║═ MSMT17╚²éĆ(g©©)öĄ(sh©┤)ō■(j©┤)╝»╔Ž▀M(j©¼n)ąą▒╚▌^Ż¼ĮY(ji©”)╣¹ūC├„═§╬─Ļ╗╠ß│÷Ą─¤o(w©▓)ąĶ╚╦╣żś╦(bi©Īo)ūóĄ─ĘĮĘ©ī”(du©¼)ė┌ė“Ę║╗»ąą╚╦į┘▒µūR(sh©¬)Š▀ėąā×(y©Łu)įĮąį�ĪŻ
ĪĪĪĪ═§╬─Ļ╗╠ß│÷┴╦ę╗éĆ(g©©)Ė³īŹ(sh©¬)ė├ĪóĖ³Š▀Ųš▀mąįĄ─ąą╚╦į┘▒µūR(sh©¬)╚╬äš(w©┤)�����Ż¼╝┤╚ń║╬īóėąś╦(bi©Īo)║ץ─║Ž│╔öĄ(sh©┤)ō■(j©┤)╝»┼c¤o(w©▓)ś╦(bi©Īo)║ץ─šµīŹ(sh©¬)╩└ĮńöĄ(sh©┤)ō■(j©┤)ŽÓĮY(ji©”)║ŽŻ¼ęįė¢(x©┤n)ŠÜ│÷Ė³Š▀ėąĘ║╗»─▄┴”Ą─ķ_(k©Īi)Žõ╝┤ė├Ą──Żą═����ĪŻ×ķ┴╦ĮŌøQ▀@éĆ(g©©)å¢(w©©n)Ņ}Ż¼═§╬─Ļ╗╠ß│÷┴╦DomainMix┐“╝▄��Ż¼═Ļ╚½Ž¹│²┴╦╚╦╣żś╦(bi©Īo)ūóĄ─ąĶŪ¾����Ż¼┐sąĪ┴╦║Ž│╔öĄ(sh©┤)ō■(j©┤)║═šµīŹ(sh©¬)öĄ(sh©┤)ō■(j©┤)ų«ķgĄ─▓ŅŠÓŻ¼į┌═Ļ╚½¤o(w©▓)╩ų╣żś╦(bi©Īo)ūóĄ─ŪķørŽ┬īW(xu©”)┴Ģ(x©¬)┐╔ęįĘ║╗»Ą─ąą╚╦į┘▒µūR(sh©¬)���Ż¼▀@śė┐╔ęį└¹ė├šµīŹ(sh©¬)╩└Įńųą┤¾ęÄ(gu©®)─ŻŪęČÓśė╗»Ą─¤o(w©▓)ś╦(bi©Īo)║×öĄ(sh©┤)ō■(j©┤)�����ĪŻ┤¾┴┐īŹ(sh©¬)“×(y©żn)▒Ē├„����Ż¼═§╬─Ļ╗╠ß│÷Ą─¤o(w©▓)ąĶ╚╦╣żś╦(bi©Īo)ūóĄ─ĘĮĘ©ī”(du©¼)ė┌ė“Ę║╗»ąą╚╦į┘▒µūR(sh©¬)Š▀ėąā×(y©Łu)įĮąį���ĪŻ
═ČĖÕÓ]ŽõŻ║chuanbeiol@163.com įöŪķšł(q©½ng)?ji©Īn)Lå¢(w©©n)┤©▒▒į┌ŠĆ(xi©żn)Ż║http://m.fishbao.com.cn/